
There are some subjects as a writer in which you know they need to be written, but at the same time you feel it necessary to steel yourself for the inevitable barrage of criticism once your work reaches its audience. Of these the latest is AI, or more specifically the current enthusiasm for Large Language Models, or LLMs. On one side we have the people who’ve drunk a little too much of the Kool-Aid and are frankly a bit annoying on the subject, while on the other we have those who are infuriated by the technology. Given the tide of low quality AI slop to be found online, we can see the latter group’s point.
This is the second in what may become an occasional series looking at the subject from the perspective of wanting to find the useful stuff behind the hype; what is likely to fall by the wayside, and what as yet unheard of applications will turn this thing into something more useful than a slop machine or an agent that might occasionally automate some of your tasks correctly. In the previous article I examined the motivation of that annoying Guy In A Suit who many of us will have encountered who wants to use AI for everything because it’s shiny and new, while in this one I’ll try to do something useful with it myself.
What is an LLM good at doing, and What Can it Do For Me?
There is plenty of fun to be had in pointing out that AI is good at making low quality but superficially impressive content, and pictures of people who won the jackpot when they were handing out extra fingers. But given an LLM to talk to, why not name a task it can do really well?
I had this chat with a friend of mine, and I agree with him that these things are excellent at summarising information. This is partly what has Guy In A Suit excited because it makes him feel smart, but as it happens I have a real world task at which that might just be useful.
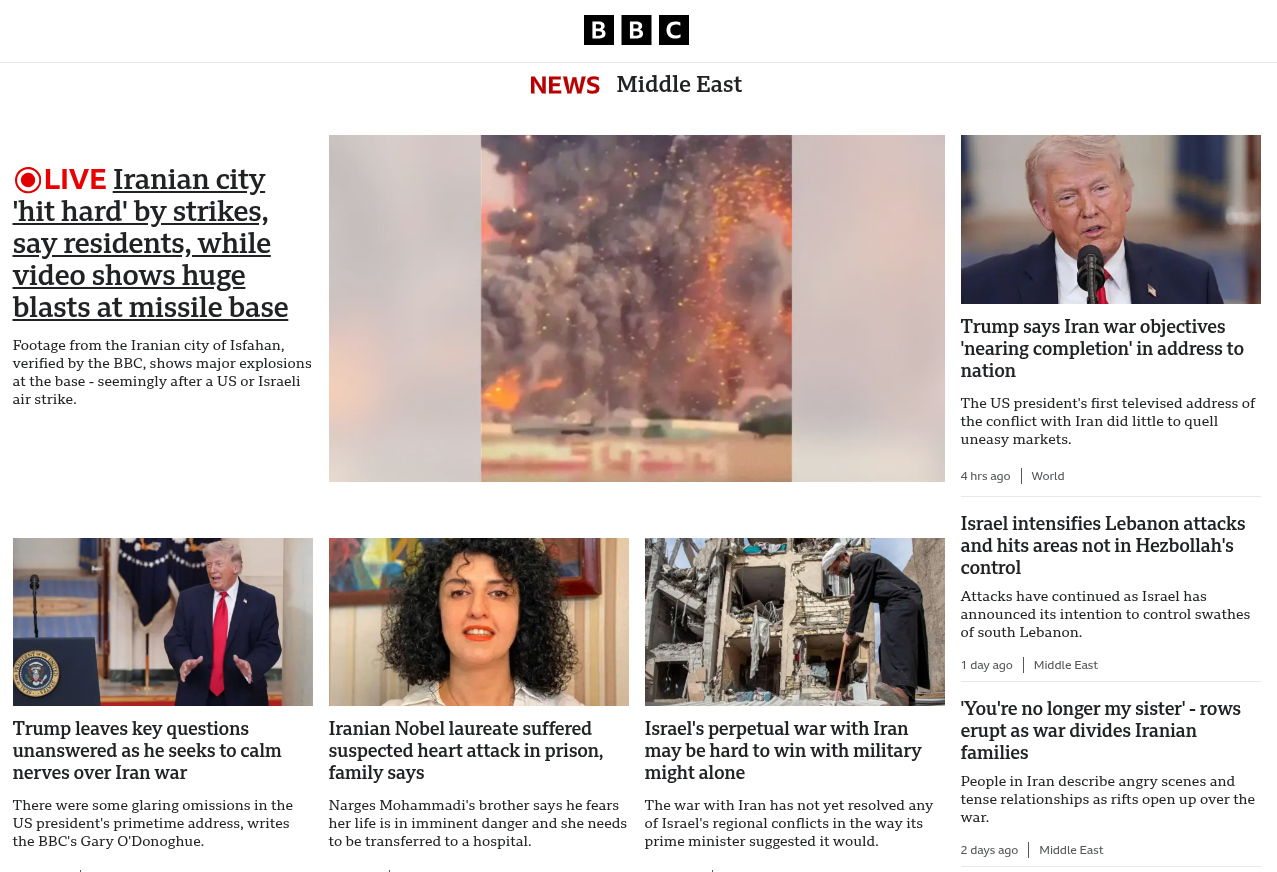
In the past I have occasionally written about a long-time side interest of mine, the computational analysis of news data. I have my own functional but rather clunky software suite for it, and the whole thing runs day in day out on a Raspberry Pi here in my office. As part of this over the last couple of decades I’ve tried to tackle quite a few different computational challenges, and one which has eluded me is sentiment analysis. Using a computer to scan a particular piece of text, and work out how positive or negative it is towards a particular subject is particularly useful when it comes to working with news analysis, and since it’s a specialist instance of summarising information, it might be suitable for an LLM.
Sentiment analysis appears at first sight to be easy, but it’s one of those things which the further you descend into it, the more labyrinthine it gets. It’s very easy to rate a piece of text against a list of positive and negative words and give it a positivity score, for example, but it becomes much more difficult once you understand that the context of what is being said. It becomes necessary to perform part-of-speech and object analysis, in order to analyse what is being said in relation to whom, and then compute a more nuanced score based upon that. The code quickly becomes a quagmire in trying to perform a task that’s easy for a human, and though I have tried, I have never really managed to crack it.
By contrast, an LLM is good at analysing context in a piece of text, and can be instructed in natural language by means of a prompt. I can even tell it how I want the results, which in my case would be a simple numerical index rather than yet more text. It’s almost sounding as though I have the means for a GetSentimentAnalysis(subject,text) function.
First, Find Your LLM
Finding an LLM is as easy as firing up ChatGPT or similar for most people, but taking this from the point of view I have, I’d prefer to run one not sitting on a large dataslurping company’s cloud servers. I need a local LLM, and for that I am pleased to say the path is straightforward. I need two things, the model itself which is the collection of processed data, and an inference engine which is the software required to perform queries upon it. In reality this means installing the inference engine, and then instructing it to pick up the model from its repository.
There are several choices to be found when it comes to an open source inference engine, and among them I use Ollama. It’s a straightforward to use piece of software that provides a ChatGPT-compatible API for programming and has a simple text interface, and perhaps most importantly it’s in the repositories for my distro so installing it is particularly easy. ollama serve got me the API on http://localhost:11434, I went for the Llama3.2 model as suitable for a workaday laptop by typing ollama pull llama3.2, and I was ready to go. Typing ollama run llama3.2:latest got me a chat prompt in a terminal. It’s shockingly simple, and I can now generate hallucinatory slop in my terminal or by passing bits of JSON to the API endpoint.
In Which I Become A Prompt Engineer
There are a few things amid the AI hype, I have to admit, that get my goat. One of them is the job description “Prompt engineer”. I’m not one of those precious engineers who gets offended at heating engineers using the word “engineer”, but maybe there are limits when “writer” is much closer to the mark. Anyway, if anyone wants to pay me scads of money to write clear English instructions as an engineer with the bit of paper to prove it I am right here, having written the following for my sentiment analyser.
I am going to ask you to perform sentiment analysis on a piece of text, where your job is to tell me whether the sentiment towards the subject I specify is positive or negative. You will return only a number on a linear scale starting at +10 for fully positive, decreasing as positivity decreases, through 0 for neutral, and decreasing further as negativity increases, to -10 for fully negative. Please do not return any extra notes. Please perform sentiment analysis on only the following text, towards ( put the subject of your query here ):
There are enough guides to using the API that it’s not worth making another one here, but passing this to the API is a simple enough process. On a six-year-old ThinkPad that’s also running the usual software of a working Hackaday writer it’s not especially fast, taking around twenty seconds to return a value. I’ve been trying it with the text of BBC News articles covering global events, and I can say that for relatively little work I’ve created an effective sentiment analyser. It will compute sentiment for multiple people mentioned in an article, and it will return 0 as a neutral value for people who don’t appear in the source text.
Wow! I Did Something Useful With It!
So in this piece I’ve taken a particularly annoying problem I’ve faced in the past and failed at, identified it as something at which an LLM might deliver, and in a surprisingly short time, come up with a working solution. I am of course by no means the first person to use an LLM for this particular task. If you want you can use it as an effective but slow and energy intensive sentiment analyser, but maybe that’s not the point here.
What I’m trying to demonstrate is that the LLM is just another tool, like your pliers. Just like your pliers it can do jobs other than the ones it was designed for, but some of them it’s not very good at and it’s certainly not the tool to replace all tools. If you identify a task at which it’s particularly good though, then just like your pliers it can do a very effective job.
I wish some people would take the above paragraph to heart.